My previous post searched for text in columns and returned a true/false result if a match was found.
This post goes one step further and lists the words found in the searches.
NOTE: Theses queries will search for any text value including numbers or dates stored as text.
Download the Excel Workbook With All the Source Data and Queries in This Post
The queries in this Excel file can be copied/pasted into the Power BI Desktop Advanced Editor and will work there too.
Enter your email address below to download the workbook with the data and code from this post.
List.Accumulate
List.Accumulate is a function that accumulates values to give a final result. It will be the basis for all the queries in this post so it's important to understand how it works.
The values it accumulates are derived from a list that is one of its input parameters.
The official syntax for the function is
List.Accumulate(list as list, seed as any, accumulator as function) as any
So you can see it takes three parameters. The first is the list I already mentioned, the second is a seed or starting value, the third is the function that defines how the values are calculated before being accumulated.
List.Accumulate acts as a loop, carrying out whatever function you create (the 3rd parameter) on the list (the first parameter).
List.Accumulate Example - Adding Numbers
Let's look at a simple example to understand how List.Accumulate works. The query is
List.Accumulate( {1, 2, 3}, 0, (state, current) => state + current)
Looking at each of those parameters we understand that
- {1, 2, 3} is the list upon which calculations will occur
- 0 is the seed, or starting value.
- (state, current) => state + current is the function that defines how values in the list are transformed
The Accumulator Function
The function (state, current) => state + current takes a little understanding.
state is the value of the function at each step/loop.
current is the current item in the list (the first parameter).
Remember that List.Accumulate loops, or iterates, through each value in the list applying the transformation specified by the accumulator function.
In this example when List.Accumulate first runs, state will be 0 which is the initial (seed) value , and current will take the value 1 which is the first value in the list.
The accumulator function adds together state and current, with the result becoming the value state takes for the next loop.
Function Syntax
(state, current) => state + current
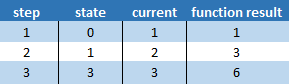
Step 1
(0, 1) => 0 + 1
Step 2
(1, 2) => 1 + 2
Step 3
(3, 3) => 3 + 3
Looking at a table showing how state and current change for each step may help understand what is happening.
List.Accumulate Example - Concatenating Text
This is very similar to adding numbers, we just change the accumulator function to join the strings in the list, with a space in between each word.
List.Accumulate( {"Great", "Barrier", "Reef"}, "", (state, current) => state & " " & current)
Starting with an empty string, a word from the list (parameter 1) is added to state on each step.

Listing Words Found in Text
Using the same data as the previous post Searching for Text Strings in Power Query, we have a column of text like so
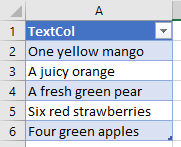
and we want to check each row in the column to see if it contains any of the words in WordList

List Found Substrings - Case Sensitive
To search for substrings, use Text.Contains. The entire query looks like this
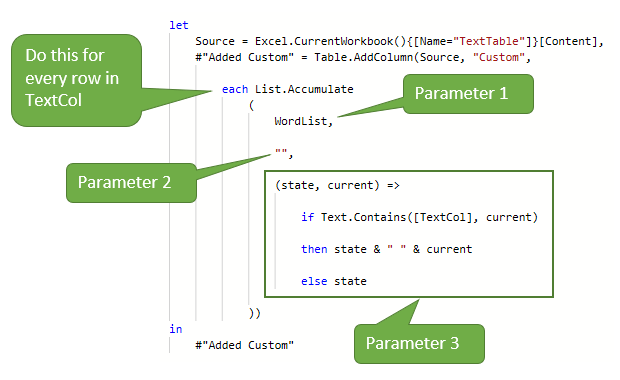
Looking at the parameters, parameter 1 (the list) is WordList, parameter 2 (the seed/initial state) is an empty string "" and parameter 3 (the accumulator function) carries out the following steps.
- if the current word in WordList appears in [TextCol]
- then state becomes state & " " & current (concatenate the strings)
- else state remains unchanged
The accumulator function is called for every word in WordList so the end result will be a string of the words found in TextCol.
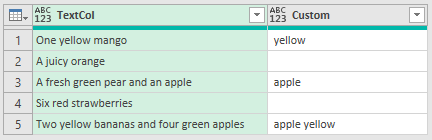
This process is carried out for every row of TextCol - that's what the each keyword signifies.
The result is another column listing the words that were found.
List Found Substrings - Case Insensitive
To make the search for substrings ignore case, add Comparer.OrdinalIgnoreCase as the 3rd parameter to Text.Contains.
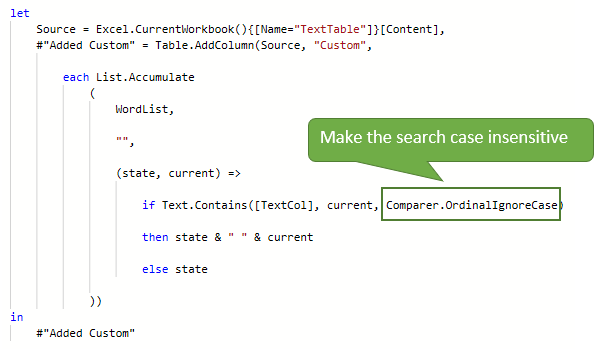
As the search is ignoring case, the words PEAR and RED are now listed.
List Exact Matches - Case Sensitive
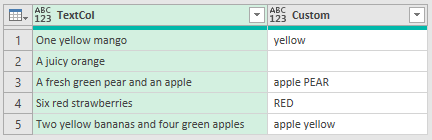
To do exact matching, that is, apple matches apple, but does not match apples, I'll use List.Contains, here's the query.

The only thing that has changed is the if part of the accumulator function which is using List.Contains. As List.Contains requires lists to work with, I need to use Text.Split to split the string in TextCol into a list of individual words.
As this is an exact match search, apple is not listed as a match in row 5.
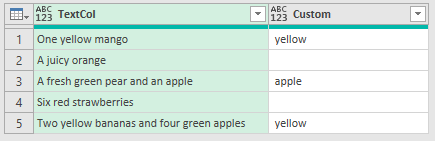
List Exact Matches - Case Insensitive
To make this search ignore case, use the Comparer.OrdinalIgnoreCase.
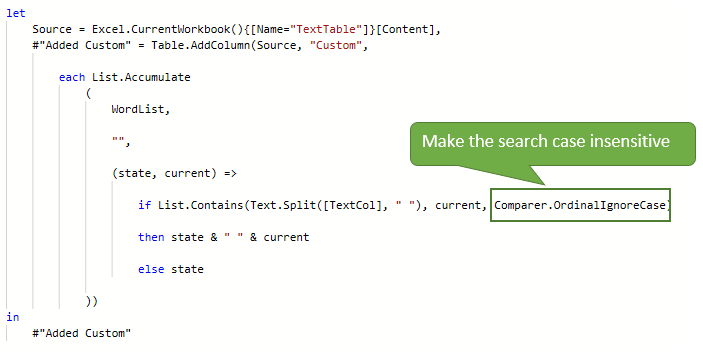
Making the search ignore case, the words PEAR and RED are listed again.
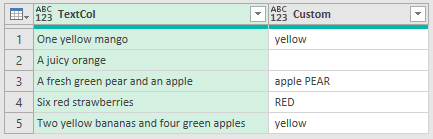
Further Useful Modifications - Counting Matches
As you can see once you get your head around what the accumulator function can do, it's easy to modify it to do other things, like count the matching words.
To create a query that looks for substrings and ignores case, you can use this code.
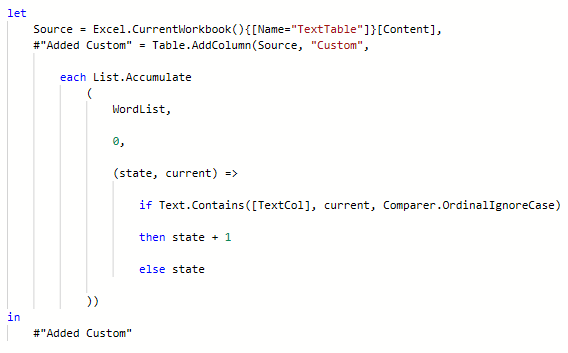
Because the function is counting, the seed value needs to be a number, so it's 0.
To do the actual counting the function just adds 1 to state each time a word is found.
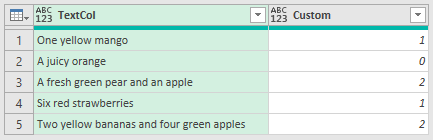
Have fun playing with List.Accumulate and writing your own accumulator functions.


Hi Phil,
Your article on matching words from a list was incredibly helpful. I’m currently working with a WORDLIST that contains phrases with spaces, such as “Six red,” and trying to find matches within a TextCol. Do you have any suggestions on how to achieve this?
Thank you for sharing your valuable knowledge!
Thanks Sara.
The code as it is will work when searching for substrings like ‘six red’. What exactly is it you are trying to do that isn’t working?
Please start a topic on our forum to continue this.
Regards
Phil
Hi Philip,
Thanks for the wonderful tutorial. This is the first time I have come across the List.Accumulate function. Your tutorial make its application very clear.
I am especially interested in the “counting matches” part. But instead of counting how many words that each row matches, I wonder whether we can count how many rows matched each word in the list.
Recently I am analyzing some survey data with multiple choice questions. Since a respondent can select one or more choices, and also specify the ‘other’ choices, each record in the column / field may contain many choices. I would like to count the number of respondents / rows that select / contain each of the choices. A simple grouping won’t work. I have found a solution online for this problem in Power BI (create a choices list table, and a Dax measure counting rows containing the choices) , but it won’t work in Power Query as some DAX functions won’t work such as CONTAINSSTRING. I wonder whether you have any solution to do this in Power Query.
You’re welcome Lee.
With your specific case, it’s hard to say how/if it can be done in PQ without seeing your data and the DAX you found.
Can you please start a topic on our forum and attach your file with the data and the DAX so i can see how it can be converted into PQ.
Phil
Hi!
Thank you for this very elegant solution!
I had found a function-based solution in the Power BI community at first, but this loads much, much faster.
Only one question:
If, in the WordList, (or in a secondary table, if needed), there was a corresponding category to each word.
Then, if one or more matches are found in the WordList, then write the corresponding category out as well?
Thanks,
Marianne
Hi Marianne,
My initial thoughts are that you could do this with a table that contains the words->categories and use a query/table merge to pull the category out once the words have been matched.
Regards
Phil
Hi Philip,
Thanks a lot, yes, that seems to be a straight forward solution.
Thanks again for the great List.Accumulate description!
KR Marianne
You’re welcome Marianne, glad you found it useful.
Regards
Phil
Hi Phil, I really like this article. It helps to understand how things work. Great job.
Based on this I am trying to build my own piece of code that would remove from TextCol all the words listed in WordList, but wiht no success so far…
Could you share some hints how to approach this?
Appreciate your thoughts…
Regards
Piotr
Thanks Piotr,
You could add a Custom Column with this code
That would be case sensitive. would that do?
Regards
Phil
When I look at the official explanation of List.Accumulate, I would never have thought in my life that I could use this M-function to solve the problem described here.
But is it also possible to search directly in multiple columns?
Hi Wilfried,
Pretty much anything is possible it just requires writing the code.
Please start a topic on our forum and give a example of what you mean I can see if I can find a solution.
Regards
Phil
Hi Phil,
thanks for your prompt reply.
This is about a question that was asked in a German forum. Here the questioner wants to search several columns of his account movements for texts of a text list to assign the individual movements to main and sub categories. for example insurances as main category and house, car, health as sub categories.
With the solution presented here this is already possible, but must be done separately for each column. I already tried to extend this in your sample folder, but unfortunately failed.
As an answer in the German forum, however, I have inserted the link to your solution. In this respect, the actual questioner can open a new topic in your forum.
Regards
Wilfried
Thanks Wilfried. If they post here that will help me as I can then see the data they re working with.
Hi Phil. Great article for match word in from list. I am working on WORDLIST which contains with spaces like “Six red” and found from TextCol. How we could get result.
Thank you for share such a wonderful knowledge.
Regards
Hi,
Have you tested the solution? It should work, Text.Contains will identify if the string contains the text you specify, no matter how many spaces there are in your words.
Thanks Phil, great post, extremely useful.
Just downloaded and tested the file, in my case it also does not match strings that contain spaces. I guess custom formula converts string to list and compares one by one with WordList, thus is not matching my target that contains space (i.e. “red apple”).
Not sure if I can fix that myself 🙁
hi Vlad,
Can you open a new topic on our forum with this problem?
Will be easier to help you there, we can upload easier files and codes?
Thank you
Hi, i have implemented the code for finding matches, using the case insensitive version. What happens is that for each line in “text col” I have every accumulated list values for each line in text col. So for example, I have 20 keywords in my worklist, and so the result is 20 repeated lines of the same line in text col, containing every keyword. so if I have 50 lines in text col, i’m getting a total of 1000 lines returned (each of the 50 has all of the 20). Is there something I’m doing wrong? i copied the code exactly….
Hi Pat,
Can you prepare a sample file with your query, so we can test it and see what is going on?
Use our forum to create a new topic and upload.
Thanks, that’s just what I wanted!
No worries 🙂
A formula-driven means for listing matched-word substrings, case insenstive (cell references drawn from your practice file):
=TEXTJOIN(” “,,IF(ISNUMBER(SEARCH(C$4:C$7,E4)),C$4:C$7,””)) and copy down.
For a case-sensitive result, substitute FIND for SEARCH.
Thanks Abbott
This is awesome, Phil. Was not aware of List.Accumulate. Thanks for the under-the-cover explanations & detailed examples.
You’re welcome Jim 🙂